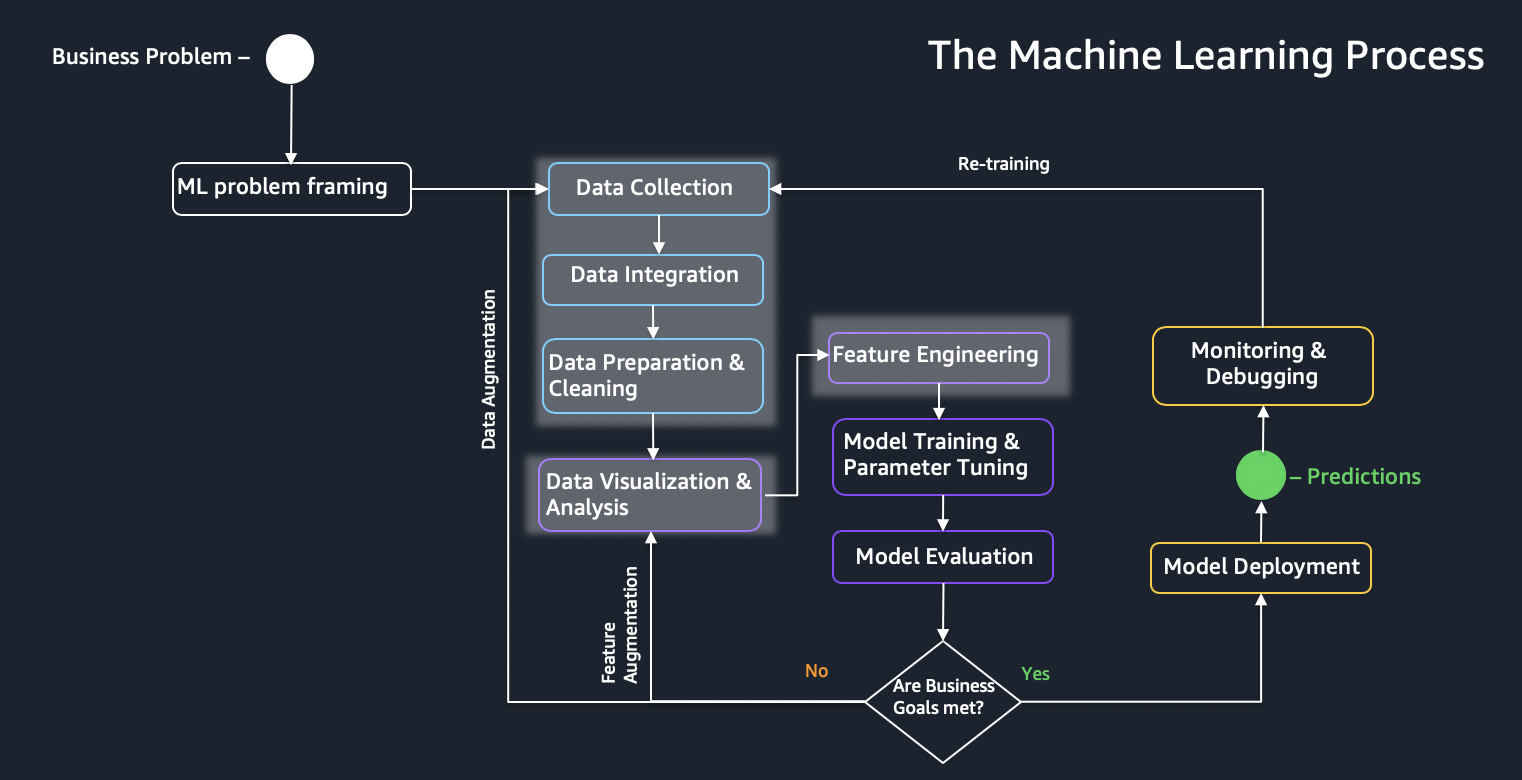
Feature Engineering
Tổng quan
Trong phần workshop này, bạn sẽ học cách sử dụng Amazon SageMaker để build, train và deploy model ML (ML). Chúng ta sẽ sử dụng thuật toán XGBoost ML phổ biến cho bài tập này. Amazon SageMaker là một dịch vụ ML được quản lý hoàn toàn theo mô-đun cho phép các nhà phát triển và nhà khoa học dữ liệu build, train và deploy các model ML trên quy mô lớn.
Việc đưa các model ML từ ý tưởng đến vận hành thực tế thường phức tạp và tốn nhiều thời gian. Bạn phải quản lý một lượng lớn dữ liệu để train model, chọn thuật toán tốt nhất để train , quản lý năng lực tính toán trong khi train nó, và sau đó deploy model vào môi trường thực tế. Amazon SageMaker làm giảm sự phức tạp này bằng cách giúp việc build và deploy các model ML dễ dàng hơn nhiều. Sau khi bạn chọn các thuật toán và framework phù hợp từ nhiều lựa chọn có sẵn, Amazon SageMaker quản lý tất cả cơ sở hạ tầng cơ bản để train model của bạn ở quy mô petabyte và deploy vào môi trường thực tế.
Trong phần này, bạn sẽ đảm nhận vai trò của một nhà phát triển ML làm việc tại một ngân hàng. Bạn đã được yêu cầu phát triển một model ML để dự đoán liệu khách hàng có đăng ký chứng chỉ tiền gửi (CD) hay không. model sẽ được train về bộ dữ liệu tiếp thị chứa thông tin về nhân khẩu học của khách hàng, phản ứng với các sự kiện tiếp thị và các yếu tố bên ngoài.
Dữ liệu đã được label để thuận tiện cho bạn và một cột trong tập dữ liệu xác định liệu khách hàng có đăng ký sản phẩm do ngân hàng cung cấp hay không. Một phiên bản của tập dữ liệu này có sẵn công khai từ kho lưu trữ ML do Đại học California, Irvine quản lý. Hướng dẫn này deploy model ML được giám sát, vì dữ liệu được label. (Học không giám sát xảy ra khi các tập dữ liệu không được label.)
Trong phần này, bạn sẽ tìm hiểu về phần được hightlight trong qui trình ML bên dưới:
- Chúng ta sẽ tập trung vào Feature Engineering và Visualization, tìm hiểu cách sử dụng Amazon SageMaker Data Wrangler để chuẩn bị data cho ML. Chúng ta cũng sẽ sử dụng Amazon SageMaker Feature để lưu trữ, sử dụng và chia sẻ các machine learning (ML) feature.