Tune model tự động
Tune model tự động.
Tune model tự động trên Amazon SageMaker, còn được gọi là Tune hyperparameters, tìm phiên bản tốt nhất của model bằng cách chạy nhiều công việc train trên data set của bạn bằng cách sử dụng thuật toán và phạm vi hyperparameters mà bạn chỉ định. Sau đó, nó chọn các giá trị hyperparameters dẫn đến model hoạt động tốt nhất, được đo bằng số liệu bạn chọn.
Ví dụ: giả sử bạn muốn giải quyết vấn đề phân loại nhị phân trên data set tiếp thị này. Mục tiêu của bạn là tối đa hóa diện tích dưới chỉ số đường cong (auc) của thuật toán bằng cách train model Thuật toán XGBoost. Bạn không biết sử dụng giá trị nào của hyperparameters eta, alpha, min_child_weight và max_depth để train model tốt nhất. Để tìm các giá trị tốt nhất cho các hyperparameters này, bạn có thể chỉ định phạm vi giá trị mà các tìm kiếm Tune hyperparameters của Amazon SageMaker để tìm kết hợp các giá trị dẫn đến công việc train hoạt động tốt nhất được đo bằng số liệu khách quan mà bạn đã chọn. Tune hyperparameters khởi chạy các công việc train sử dụng các giá trị hyperparameters trong phạm vi mà bạn đã chỉ định và trả về công việc train với auc cao nhất.
- Chúng ta sẽ điều chỉnh bốn hyperparameters trong ví dụ này:
- eta: Thu nhỏ kích thước bước được sử dụng trong các bản cập nhật để ngăn tình trạng overfitting. Sau mỗi bước tăng cường, bạn có thể trực tiếp nhận được thông số weight của các new feature. Tham số eta thực sự thu nhỏ thông số weight của feature để làm cho quá trình tăng cường tiết kiệm hơn.
- min_child_weight: Tổng thông số weight tối thiểu (hessian) cần thiết trong node child. Nếu bước phân vùng cây dẫn đến một leaf node có tổng thông số weight nhỏ hơn min_child_weight, thì quá trình build sẽ dừng thực hiện phân vùng tiếp theo. Trong các mô hình hồi quy tuyến tính, điều này đơn giản là tương ứng với một số lượng tối thiểu các trường hợp cần thiết trong mỗi node. Qui mô thuật toán càng lớn thì hiệu quả tiết kiệm càng cao.
- alpha: L1 thuật ngữ chính quy trên thông số weight. Việc tăng giá trị này làm cho các model hoạt động tiết kiệm hơn.
- max_depth: Độ sâu tối đa của cây. Việc tăng giá trị này làm cho mô hình phức tạp hơn và có khả năng bị overfit.

- Tiếp theo, chúng ta sẽ chỉ định chỉ số (metric) mục tiêu mà chúng ta muốn điều chỉnh và định nghĩa của nó, bao gồm regular expression (Regex) cần thiết để trích xuất chỉ số đó từ CloudWatch logs của công việc training.
- Vì chúng ta đang sử dụng thuật toán XGBoost tích hợp sẵn, nó tạo ra hai chỉ số được xác định trước: validatioN: auc và training : auc và chúng ta đã chọn giám sát chỉ số validation: auc như bạn có thể thấy bên dưới.
- Trong trường hợp này, chúng tôi chỉ cần chỉ định tên chỉ số và không cần sử dụng regex. Nếu bạn sử dụng thuật toán của riêng mình, thì thuật toán của bạn sẽ tự tạo ra các chỉ số . Trong trường hợp đó, bạn sẽ cần thêm đối tượng MetricDefinition tại đây để xác định định dạng của các chỉ số đó thông qua regex, để SageMaker biết cách trích xuất các chỉ số đó từ CloudWatch logs của bạn.

- Bây giờ, chúng ta sẽ tạo một đối tượng Hyperparameter Tuner, chúng ta sẽ truyền vào đối tượng đó:
- XGBoost estimator mà chúng ta đã tạo ở trên
- Tên và định nghĩa chỉ số mục tiêu
- Phạm vi hyperparameters chúng ta muốn.
- Điều chỉnh cấu hình tài nguyên chẳng hạn như Tổng số công việc train sẽ chạy và số lượng công việc train có thể chạy song song.
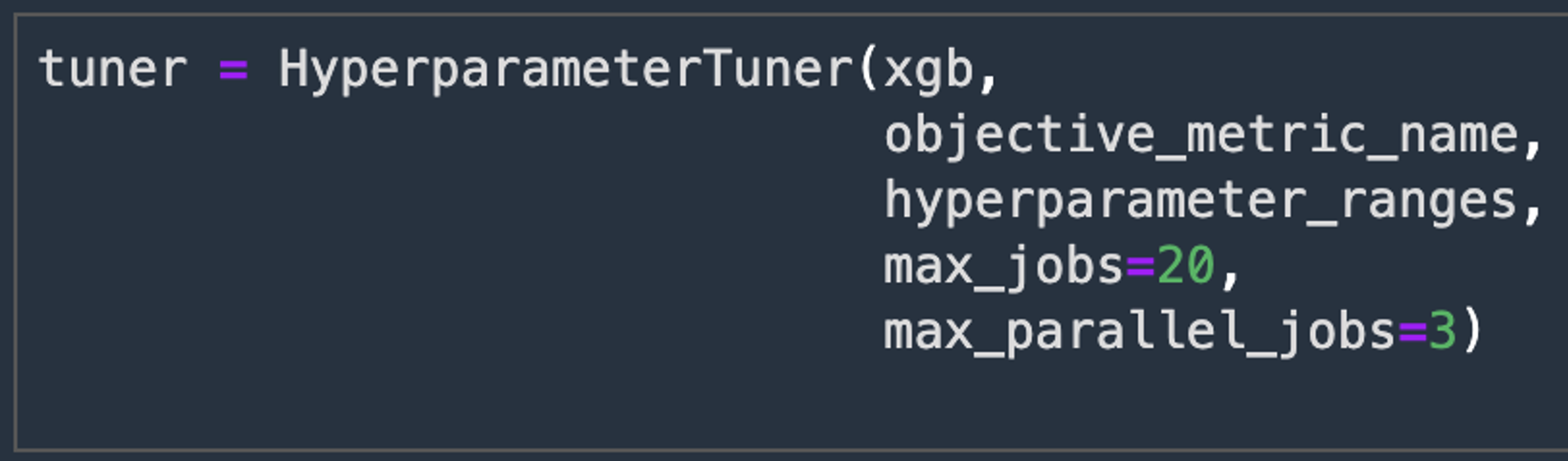
- Bây giờ chúng ta có thể khởi chạy công việc điều chỉnh hyperparameters bằng cách gọi hàm fit (). Sau khi công việc điều chỉnh hyperparameters được tạo.

- Chúng ta có thể vào bảng điều khiển SageMaker để theo dõi tiến trình của công việc điều chỉnh hyperparameters cho đến khi hoàn thành.
- Click Training.
- Click Hyperparameter tuning jobs.
- Click tên job.
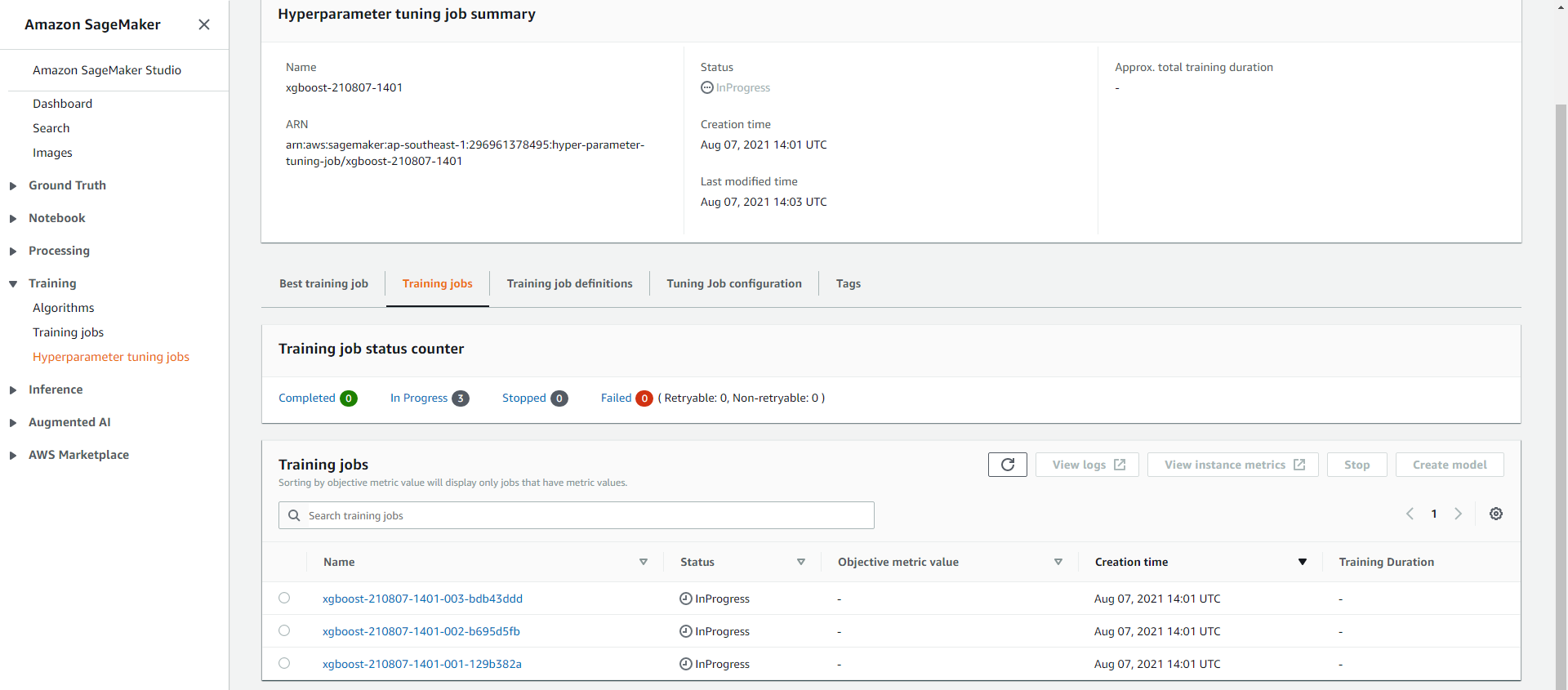
- Chúng ta có thể theo dõi chi tiết các training jobs tại giao diện summary.
- Chúng ta cũng có thể kiếm tra nhanh trạng thái job tuning hyperparameters bằng cách sử dụng lệnh bên dưới.
- Trạng thái “InProgress” có nghĩa là công việc đã bắt đầu thành công.

- Trạng thái hoàn tất thể hiện công việc tuning hyperparameters đã hoàn tất.
- Sau khi hoàn thành công việc tune model, bạn có thể chọn công việc train có hiệu suất tốt nhất, deploy, thực hiện predict và đánh giá model như các bước đã thực hiện trước.
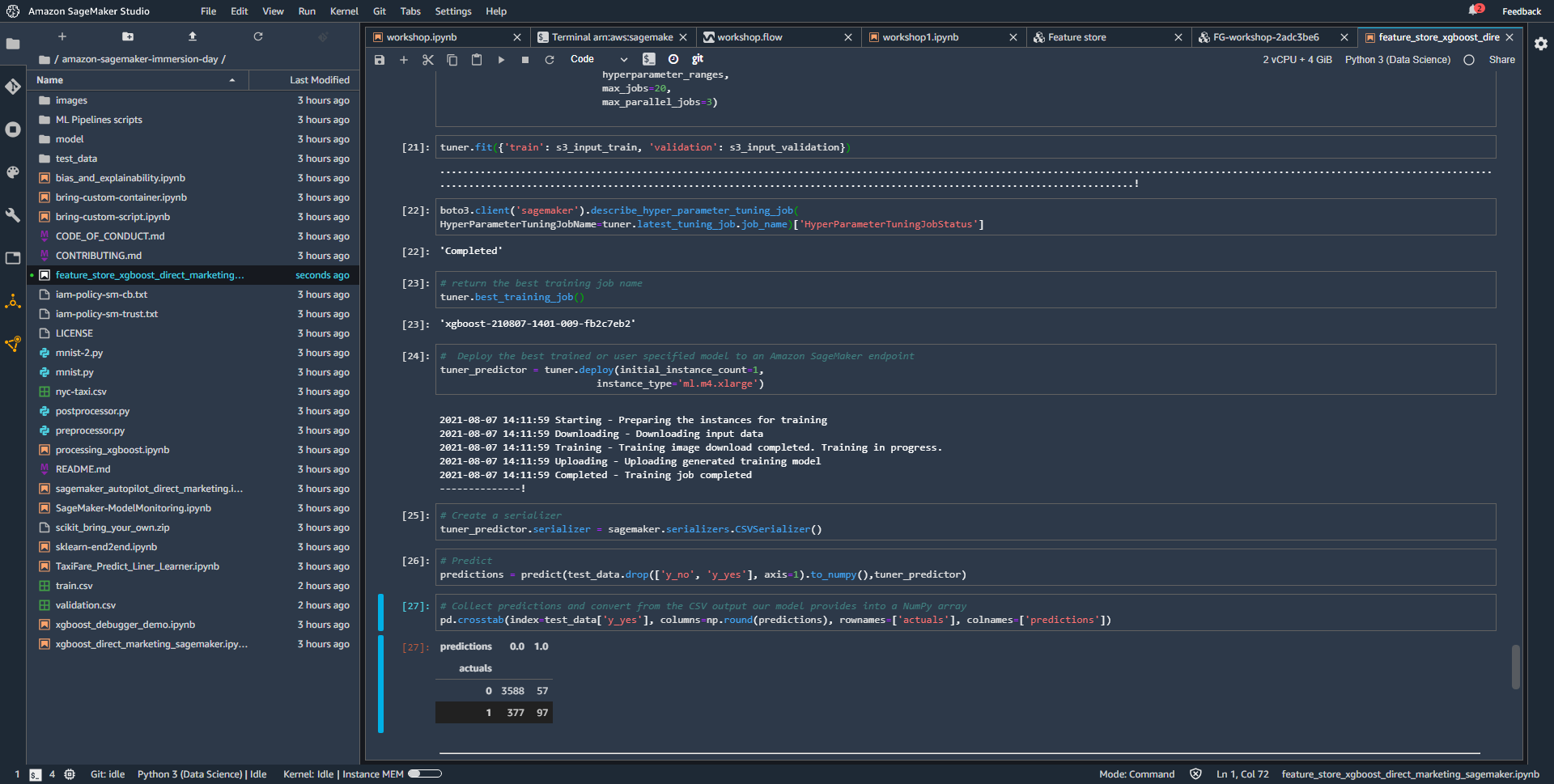
Trong workshop này, bạn đã đi qua quá trình build , train , tune và deploy model XGBoost bằng cách sử dụng thuật toán tích hợp sẵn của Sage maker.
Chúng ta cũng đã sử dụng SageMaker Python SDK để build, tune và deploy model. Bạn cũng đã làm quen với giao diện của SageMaker trong khi thực hiện train, automatic model tuning và deploy model vào môi trường sử dụng.