Đánh giá hiệu suất model
Đánh giá hiệu suất model.
Trong bước này chúng ta sẽ thực hiện format lại CSV data, sau đó chạy model để thực hiện tiên đoán. Chúng ta sẽ đánh giá hiệu suất của model sử dụng confusion matrix. Trong trường hợp này chúng ta sẽ tiên đoán liệu khách hàng có đăng ký gửi tiền theo kỳ hạn(1) hay không(0).
- Đầu tiên chúng ta sẽ cần xác định cách thức truyền data và nhận data từ endpoint. Data của chúng ta hiện được lưu trữ dưới dạng NumPy arrays trong bộ nhớ của notebook instance. Để gửi nó thông qua HTTP POST request, chúng ta sẽ thực hiện serialize data như một CSV string và decode kết quả CSV đó.
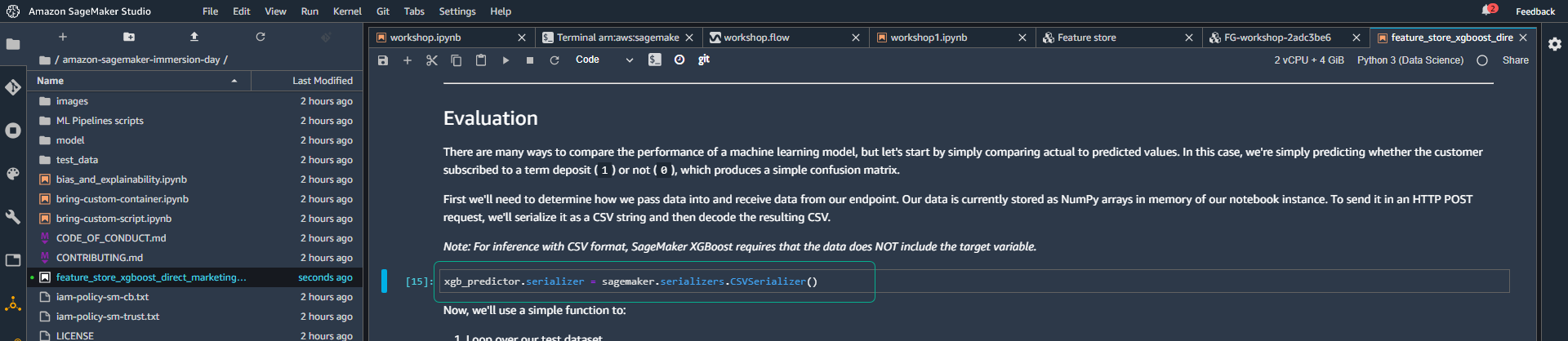
Khi thực hiện inference với định dạng CSV, SageMaker XGBoost yêu cầu data không bao gồm biến số mục tiêu.
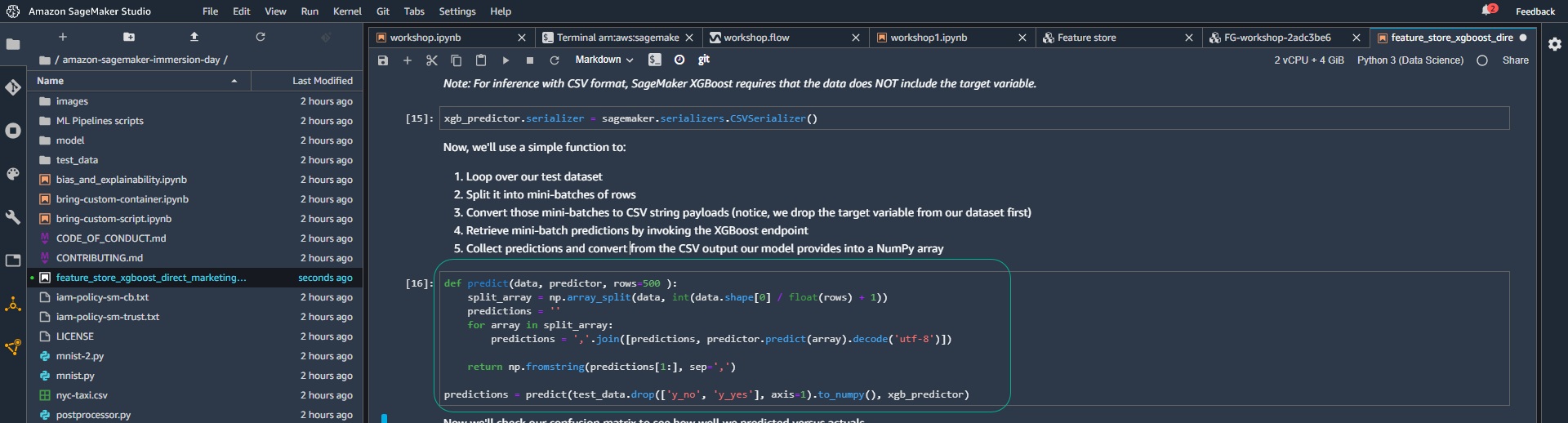
- Tiếp theo chúng ta sẽ tạo một hàm đơn giản để :
- Lặp lại tập test data set của chúng ta.
- Chia nó thành các nhóm nhỏ theo hàng.
- Chuyển đổi các nhóm nhỏ đó thành chuỗi nội dung CSV (lưu ý, trước tiên chúng ta loại bỏ biến mục tiêu khỏi data set).
- Truy xuất các dự đoán theo nhóm nhỏ bằng cách gọi XGBoost endpoint.
- Thu thập các dự đoán và chuyển đổi từ đầu ra CSV mà model của chúng ta cung cấp thành một NumPy array.
- Kiểm tra kết quả confusion matrix để xem hiệu suất kết quả tiên đoán so với kết quả thực tế.
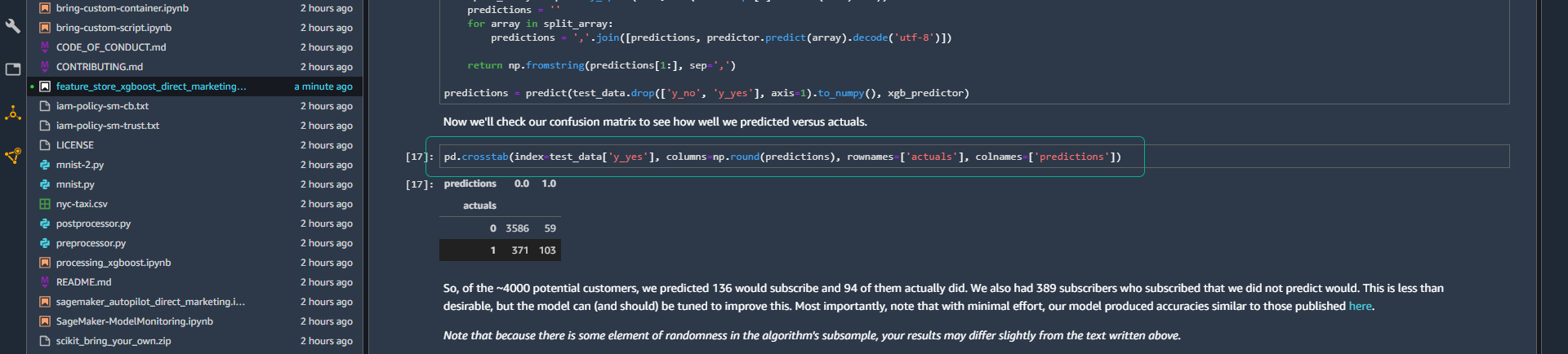
Như vậy, trong số ~ 4000 khách hàng tiềm năng, mô hình dự đoán 59 người sẽ đăng ký và 103 người trong số họ thực sự đã đăng ký. Chúng ta cũng có 371 người đăng ký thực sự đăng ký mà mô hình đó không dự đoán sẽ đăng ký.
| N~ 4000 | Predicted : No | Predicted : Yes |
|---|---|---|
| Actual : No | 3586 | 59 |
| Actual : Yes | 371 | 103 |